Blobber
Details on the blobber, the actual storage provider for user data

The blobber is the most important provider when it comes to hosting users' data. It provides actual storage space to host this data on its file system and gets rewards in return. Users can host their own blobber on premises or on our dedicated servers through the Chimney Webapp.
Core responsibilities of the Blobber
Host users' data on its file system
Maintain the correctness and availability of the users data on-demand.
Provide a highly-available interface (currently an HTTP API) for the users to access or modify their data.
Answer the challenges so it can get rewards
Logical component of the Blobber's Process
The Sharder Process consists of multiple workers (technically, lightweight execution threads or goroutines in the Go literature). Following are the most important workers running the miner operations
Allocation Sync Worker
An Allocation is like a contract between the user and Züs network about some data the user need to host on the Network. One of the terms that the user choose during creating the allocation is the blobbers that will host their data based on this allocation. Since this coordination occurs between the user and the blockchain network (miners and sharders to simplify), the blobber knows nothing about the allocation unless it requests this data from the network using one of the endpoints of the Sharder API. This worker periodically polls this endpoint for updates and persists the information of the new allocations
Challenge Workers
Challenges is how the blobbers get time-based rewards for storage. In simple words, a challenge is a validation inquiry of a portion of the data that should be hosted by some blobber i.e. trying to check if the blobber is really hosting this portion of data or not. They're generated by the network using a special type of transactions called Built-in Transactions that are autogenerated by the network on each block generation. A challenge is generated:
For a specific Blobber
Asking about a specific Allocation
And a specific Block of data in this allocation
Similar to Allocations, Challenges are generated and kept in the blockchain network and the blobber knows nothing about it until it requests this data from the network also using one of the endpoints of the Sharder API. It then answers those challenges and send its response back to the network, which in turn validates the answer and either rewards or penalizes the blobber, based on the answer. These tasks: polling the network for new challenges, answering the challenges and sending the answers to the network, are the responsibility of these workers. More about challenges are to come in the Challenges page.
Read/Write Markers Workers
Read Markers are chique-like structures sent by the blobbers to the network in order to get fees of read operations from the client's wallet, same for Write Markers for write operations. Both will be discussed in more details in the Read/Write Markers page. Those workers handle the markers flow until the marker is fulfilled and redeemed.
Health Check Worker
A worker responsible for the heartbeats of the blobber which are signs of the blobber liveness. It works by generating a health check transaction periodically and communicating it with the network.
Update Settings Worker
The owner of the blobber - the user who created the blobber on Chimney - can update the settings of the blobber. However, they will not be communicating with the blobber directly, this settings update operation is submitted as a transaction to the network, thus unseen by the blobber unless it requests this data from the network using the Sharder API. So the responsibility of this worker is to sync blobber settings with the network periodically.
The Blobber HTTP API
The blobber exposes an HTTP API as an interface of the file operations the users need to execute on their data. It's discussed in more detail in the Blobber API page.
Blobber Settings
These are the settings that the owners can change about their blobbers.
Those settings can only be changed by the owner's wallet.
Capacity (Bytes)
This is the maximum capacity that the blobber offers to use for hosting users' data.
Read Price (SAS/GB/Time Unit)
SAS is the smallest countable unit of the ZCN token. One ZCN is 10^10 SAS
This is how much the user pays for read operations against this blobber, it's calculates per GB per Time Unit where Time Unit is one of the storage configuration elements.
Write Price (SAS/GB/Time Unit)
This is how much the user pays for write operations against this blobber, it's calculated per GB per Time Unit where Time Unit is one of the storage configuration elements
Max Offer Duration (duration string e.g. 700h - 3m - ..)
This is how long the blobber can keep its prices without change. After this duration elapses, the blobber's prices change and all allocations need to be updated.
Min Stake (SAS)
This is the least amount the blobber can be staked with by a single client. Staking is discussed in more detail in the Tokenomics page.
Max Stake (SAS)
This is the largest amount the blobber can be staked by a single client. Staking is discussed in more detail in the Tokenomics page.
Max Number of Delegates (no unit)
This is the maximum number of clients that can be delegated to the blobber by staking. Delegation is discussed in more detail in the Tokenomics page.
Service Charge (Decimal, 0 to 1)
This is the ratio the blobber receives from each storage reward it earns before the rest is distributed over its delegates.
URL (text)
The URL of the homepage of the blobber.
Not Available (boolean)
Whether the blobber is available for hosting users' data or not.
Blobber Protocols
File Hash
There are 3 hashes for a file on Blobber:
Actual File Hash
it is used to verify the checksum of downloaded file on clients. It is the hash of original file. It is
reference_objects.actual_file_hashin database.Content Hash
it is used to verify the checksum of uploaded data blocks on blobber server. It is hash of data blocks that is sharded by
ErasureEncoderon client and uploaded on a blobber. It isreference_objects.content_hashin database.Challenge Hash
it is used to verify challenge on validator based on challenge protocol. It is
reference_objects.merkle_rootin database.
Hash Method
Actual File Hashis computed by sha256Content Hashis computed by MerkleTree.
A hash tree or Merkle tree is a tree in which every leaf node is labelled with the cryptographic hash of a data block, and every non-leaf node is labelled with the cryptographic hash of the labels of its child nodes.
For better performance on memory and persistence, we have a CompactMerkleTree here.
What is CompactMerkleTree?
It is a MerkleTree which nodes are labelled and removed as soon as possible.
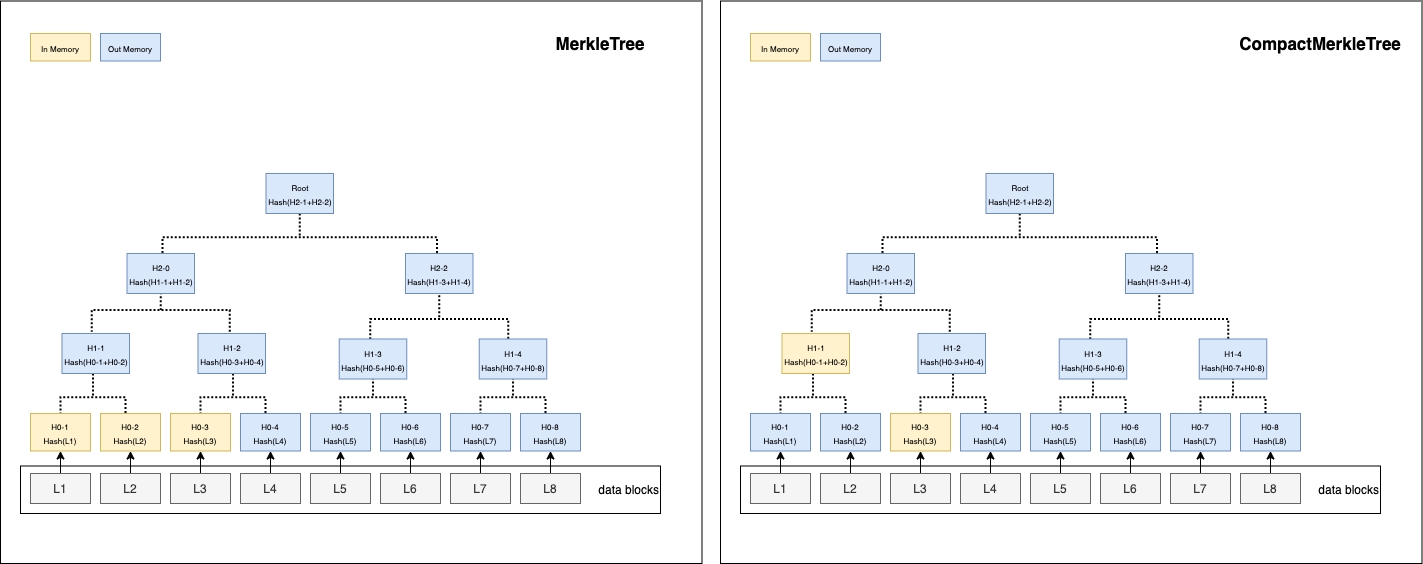
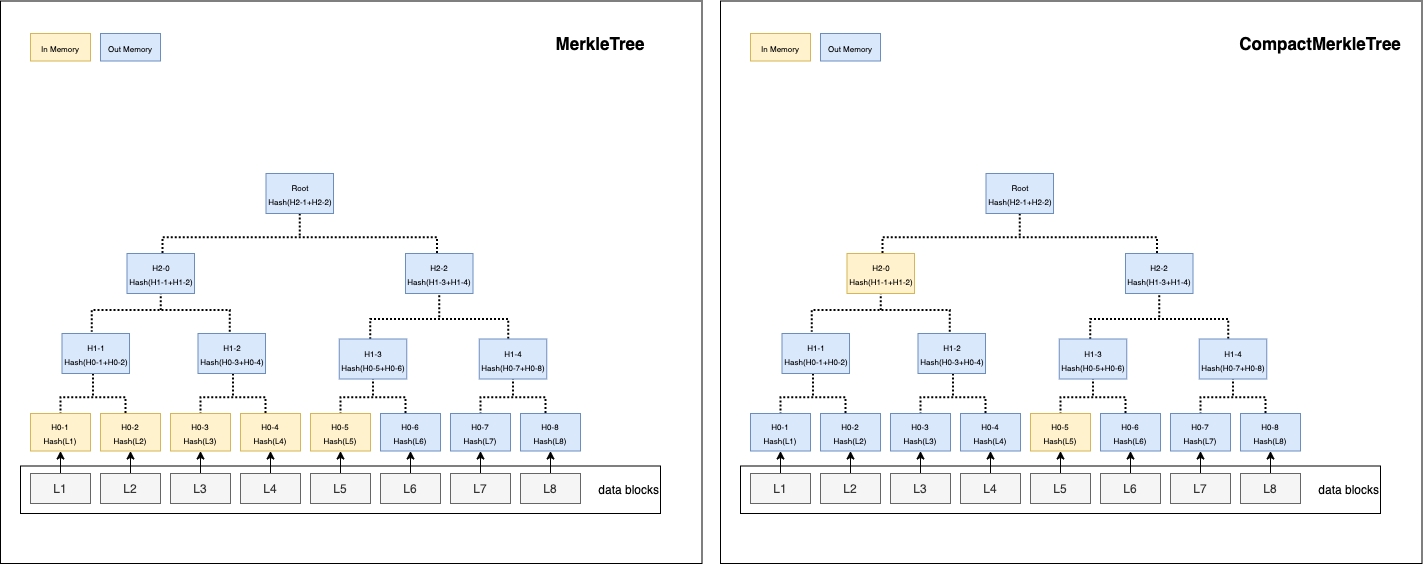
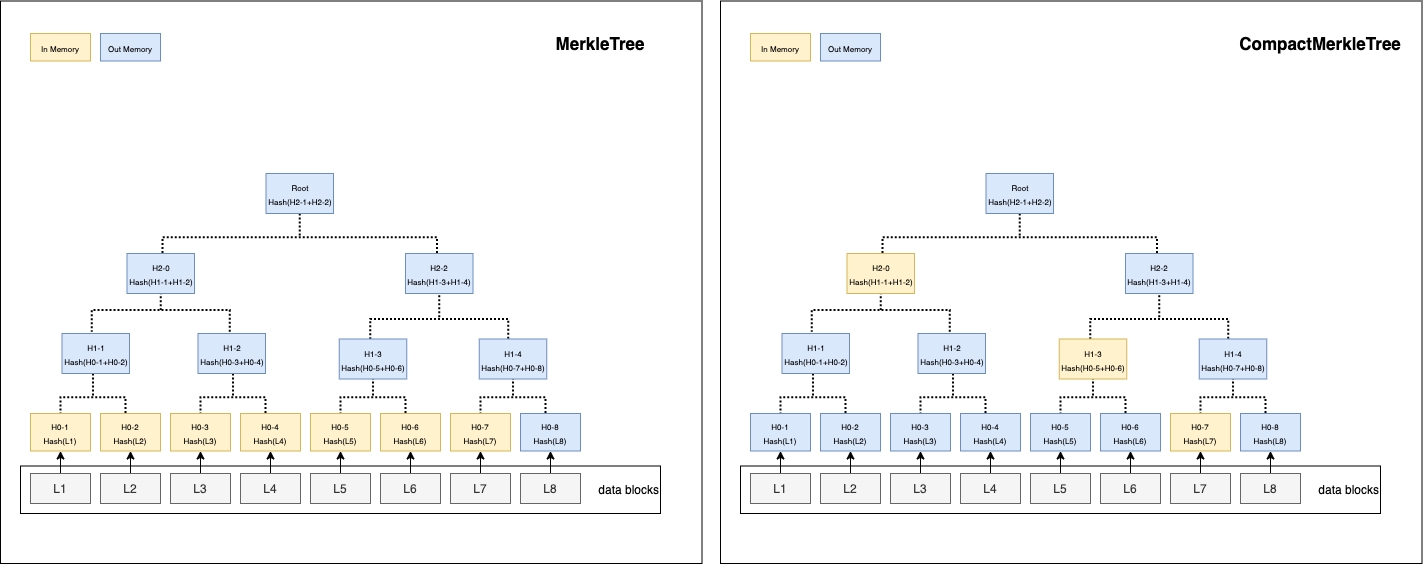
In MerkleTree, all leaf nodes are added and kept in memory before computing hash. It computes hash from leaf nodes to root node level by level.
In CompactMerkleTree, they will be computed instantly once two child nodes are added, save the binary hash on their parent node. The two child nodes are removed from memory.
For example:
the size of the data block is chunk_size.
a data block can be released from memory once it's hash is computed and added into MerkleTree as leaf node.
In Memorymeans it has to be kept in memory for computing hash.Out Memorymeans it is safe to release from memory or is not added in memory yet.
Trees in memory when 3 hash leaves are added
Trees in memory when 5 hash leaves are added
Trees in memory when 7 hash leaves are added
CompactMerkleTree is better than MerkleTree to persist the tree to disk or keep it in memory.
Challenge Hash is also computed by MerkleTree. For Outsourcing Attack, we have a FixedMerkleTree here.
Outsourcing Attack
To ensure each storage server commits resources and doesn’t outsource its tasks, our protocol requires that the content for verification is 64 kB, derived from the full file fragment. Here’s how it works:
File Division: The file is split into ( n ) 64 kB fragments, each assigned to a storage server.
Chunking: Each 64 kB fragment is further divided into 64-byte chunks, resulting in 1024 chunks per fragment.
Hashing: Data at each index across the blocks is treated as a continuous message and hashed. These 1024 hashes form the leaf nodes of a Merkle Tree.
Merkle Tree: The root of the Merkle Tree is used to aggregate file hashes up to the directory/allocation level. The Merkle proof provides the path from the leaf to the file root and then to the allocation level.
To pass a challenge for a specific index (1 to 1024), a dishonest server would need to download all content and construct the leaf hash, discouraging outsourcing and ensuring genuine resource commitment.
What is FixedMerkleTree?
It is a MerkleTree in which every leaf node is labelled with the MerkleTree hash of a data block and every non-leaf node is labelled with the cryptographic hash of the labels of its child nodes. It always has fixed 1024 leaf nodes. That is why we call it FixedMerkleTree.
See detail on example:
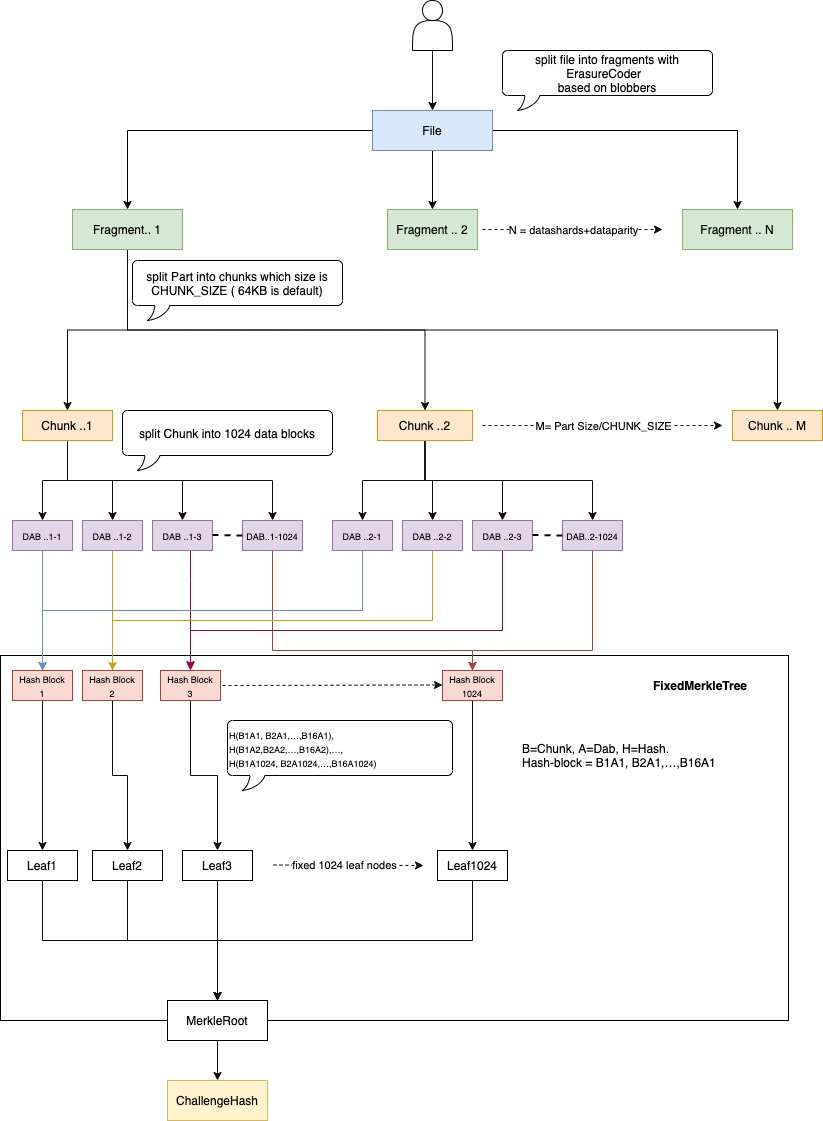
Challenge Hash was computed hash with MerkleTree in which every leaf node is labelled with sha3, and every non-leaf node is labelled with the cryptographic hash of the labels of its child nodes. sha3 asks fully load block..1-n,block..2-n...block..1024-n on memory before computing the hash for the leaf node L..n. I have the same issue as sha1 in Actual File Hash and Content Hash. That is why every leaf node is labelled with CompactMerkleTree instead of sha3 now.
Last updated